Clenvoric Route Index Chain Forker: A Clear Guide to the Workflow Concept
Clenvoric Route Index Chain Forker sounds like a heavy technical phrase, but the core idea can be explained in plain English. It points to a system that organizes routes, tracks indexed data, follows chain activity, and handles forks or alternate paths safely. While “Clenvoric” does not appear to be a widely known public tool or platform, the phrase can still work as a useful concept for understanding how modern routing, indexing, and blockchain-style data flows are managed.
What Does Clenvoric Route Index Chain Forker Mean?
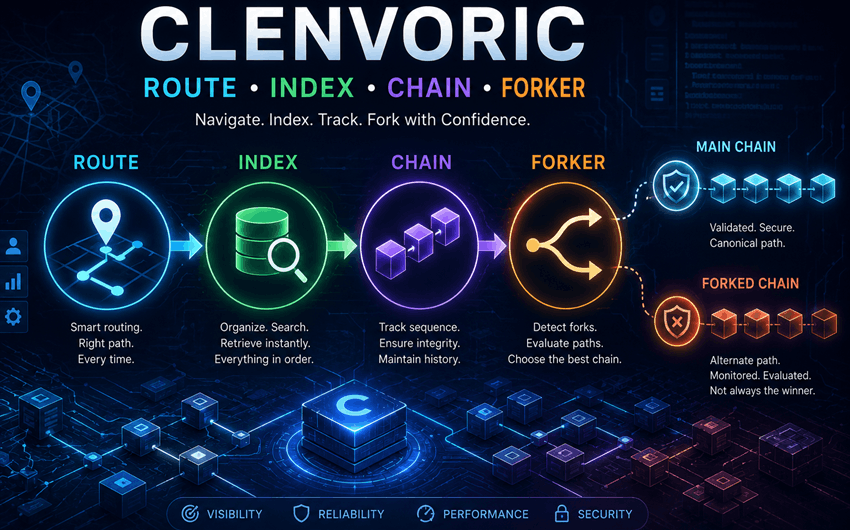
The phrase can be broken into five parts: Clenvoric, route, index, chain, and forker. Each word suggests a different piece of a technical workflow.
Clenvoric appears to be the custom or branded part of the phrase. It may be an internal project name, fictional system name, software module, or concept label. Since there is no clear public record of it as a known product, it is best understood as a placeholder name for the larger workflow.
Route refers to the path a request, user action, data packet, or process takes through a system. In web apps, routes decide what page or view appears. In backend systems, routes can decide where traffic, jobs, or API calls go.
Index refers to organized data that can be searched, queried, or retrieved quickly. Indexing is important because raw data is often too slow or messy to use directly. A good index turns scattered information into something structured and useful.
Chain can refer to a linked sequence of events, records, blocks, tasks, or dependencies. In blockchain systems, a chain is a growing record of blocks. In general software design, a chain can also mean a connected process where each step depends on the one before it.
Forker suggests a system that handles forks. A fork happens when one path splits into two or more possible paths. In software, that may mean a branch of code. In blockchain, it may mean competing chain histories. In workflow systems, it may mean different process versions running at the same time.
Together, Clenvoric Route Index Chain Forker can be understood as a system that tracks routes, builds indexes, follows chain history, and manages forks when paths split.
Why This Concept Matters
Modern systems are rarely simple. A user may click through several pages. An app may call multiple APIs. A blockchain indexer may scan new blocks. A deployment tool may track many versions of the same project. When all of these pieces move at once, teams need a way to understand what happened, where it happened, and which version is correct.
That is where a route-index-chain-forker concept becomes useful. It gives structure to movement and change. It can answer questions like:
- Which route did the request follow?
- Which data was indexed?
- Which chain state was active at the time?
- Did a fork happen?
- Which branch should be trusted?
- Can the system roll back or recover if the wrong path was followed?
These questions matter in software, blockchain, data pipelines, content systems, and infrastructure tools. Without clear routing and indexing, teams can lose track of system behavior. Without fork handling, they may accept the wrong version of events.
The Route Layer: Directing Movement Through the System
The route layer is the first part of the concept. It decides where things go.
In a web application, routes connect URLs to pages or components. For example, a parent route may have a default child route that appears when no deeper path is selected. This keeps navigation organized and predictable.
In backend systems, routes can be more complex. A request might be sent to one service for authentication, another for payment, another for storage, and another for logging. A route index can help track each step so the system does not become a black box.
For a Clenvoric-style system, the route layer would likely do three things. First, it would define approved paths. Second, it would record which path was used. Third, it would make it easier to debug problems when traffic or data moves in the wrong direction.
The Index Layer: Making Data Easy to Find
The index layer gives the system memory. It takes raw activity and turns it into organized records.
Without indexing, a system may still store data, but finding the right data becomes slow and painful. Indexing allows users, apps, and services to ask sharper questions. Instead of digging through every event manually, the system can quickly locate the route, block, record, branch, or version that matters.
In a blockchain-style environment, indexing is especially important. Blockchains produce long streams of data. Apps often need a cleaner way to read that data, such as by account, transaction, smart contract event, token, timestamp, or block number.
A route index could also be useful outside blockchain. For example, a large app might index user navigation paths. A logistics system might index delivery routes. A deployment platform might index build paths and release stages. In each case, the index turns movement into searchable structure.
The Chain Layer: Tracking Order and History
The chain layer is about sequence. It tells the system what happened first, what happened next, and what depends on what.
In blockchain, this idea is literal. Blocks are linked together in order. Each new block builds on a previous block. But the same idea also applies to many other systems. A content workflow can have a chain of drafts, reviews, approvals, and publishing steps. A software pipeline can have a chain of commits, builds, tests, and releases.
The value of the chain layer is traceability. If something goes wrong, the team can look back and see where the issue started. Did the wrong route fire? Did the index miss an event? Did a fork create two competing versions? Did the system follow an outdated chain state?
A strong chain layer helps prevent confusion because it gives every action a place in the timeline.
The Forker Layer: Handling Splits Without Chaos
The forker layer is the most sensitive part of the concept. Forks are not always bad. In many systems, they are normal. Developers create code branches. Blockchain networks may temporarily see competing chains. Workflow tools may split a project into separate versions for testing.
The problem is not the fork itself. The problem is unmanaged forks.
If a system does not know how to handle forks, it may index the wrong data, send users down the wrong route, or treat a temporary branch as the final truth. That can create broken records, duplicate work, failed deployments, or incorrect reports.
A Clenvoric Route Index Chain Forker would ideally detect when a fork happens, track both paths, compare their status, and decide which one should become the trusted path. In blockchain language, this is similar to watching for the canonical chain. In software workflow language, it is similar to deciding which branch should be merged, archived, or rejected.
How a Clenvoric-Style System Might Work
A practical Clenvoric-style workflow might begin with route detection. The system sees a request, event, block, or task and records where it came from. Then it assigns that activity to a route.
Next, the index layer stores key details. These might include timestamps, IDs, source systems, parent records, related routes, chain position, and current status.
After that, the chain layer places the event into sequence. It checks whether the event follows the expected order. If it does, the system continues. If not, the system may flag it for review.
Finally, the forker layer watches for splits. If two valid paths appear, the system does not panic. It tracks both, waits for more information if needed, and follows rules for choosing the correct path.
This kind of design is useful because it separates the workflow into clear jobs. Routes move activity. Indexes organize activity. Chains order activity. Forkers manage split activity.
Common Use Cases
A Clenvoric Route Index Chain Forker concept could apply to several technical areas.
Web application routing: It could track how users move through nested routes, default pages, redirects, and protected views.
Blockchain indexing: It could help index on-chain events while watching for chain reorganizations or forked histories.
API infrastructure: It could record which services handled a request and whether the request followed the expected path.
Deployment pipelines: It could track build routes, release chains, rollback paths, and branch splits.
Data processing systems: It could organize event streams and handle cases where two versions of a data path appear.
Audit and compliance tools: It could help teams prove which route was used, which record was indexed, and which chain of events led to a final decision.
Benefits of This Type of Workflow
The biggest benefit is clarity. A route-index-chain-forker model helps teams understand movement, data, order, and divergence in one system.
It can also improve debugging. When something breaks, the team can inspect the route, check the index, review the chain, and see whether a fork caused the issue.
Another benefit is safer automation. Automation is powerful, but only when the system knows what it is acting on. A strong index and chain record can prevent automated tools from making decisions based on stale or incorrect data.
It can also improve trust. Users and teams are more likely to rely on a system when it can explain why a certain path, record, or version was chosen.
Risks and Limitations
This concept can become too complex if it is overbuilt. Not every project needs a full route-index-chain-forker system. Small apps and simple workflows may only need basic routing and logging.
Another risk is false confidence. An index can be incomplete. A route can be misconfigured. A chain can show order without proving correctness. A fork handler can choose the wrong branch if the rules are weak.
That is why human review, testing, monitoring, and clear documentation still matter. The system should support good decisions, not replace careful thinking.
Final Thoughts
Clenvoric Route Index Chain Forker is best understood as a conceptual name for a structured technical workflow. It brings together four important ideas: routing, indexing, chain tracking, and fork handling.
Even if “Clenvoric” is not a known public tool, the model behind the phrase is useful. Systems need clear routes, searchable indexes, ordered histories, and safe ways to handle split paths. When these parts work together, teams can build software and data workflows that are easier to trace, easier to debug, and safer to scale.





